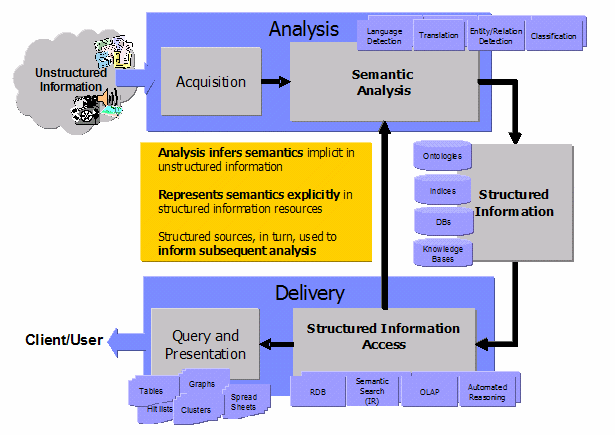
When I was attending a talk of
Thilo Götz on UIMA, the word came to 'Semantic Search'. Up to that point in time, I was quite sure about the meaning of this term. But, I had to realize that several people think in different ways about it.
As far as I have understood the meaning of that term, '
Semantic Search' refers to
all techniques and activities that deploy semantic web technology on any stage of the search process. Thilo Götz (and he's not alone with that) refered to 'Semantic Search'
as a 'traditional' search engine that is using a semantically enriched search index (i.e. a search index that incorporates ontologies or information/relationships infered from ontologies).
From my point of view the later definition refers only to a part of the whole process. Let's take
a brief look at search engine technology: You have to consider the
index generation (including the crawling processes, information retrieval for creating descriptors, inverse indexing, overall ranking, clustering, ...) as well as the
user interaction (including query string evaluation, query string refinement, visualization of search results, navigation inside the search domain), not to forget
personalization (concerning a personalized ranking of the search results including some kind of 'pre-selection' according to the personal information needs of the user, a personalized visualization, etc.) -- which will become of much more importance in the nearby future.
But, to generate a
semantic search index there are several possibilities to consider:
- Using unstructured web-data (html, etc. ...) in combination with information retrieval techniques to map the information represented in the web-data to (commonly agreed) ontologies of well defined semantic.
- Using semi-structured web-data that already include links to well defined ontologies (being commonly agreed upon or at least being mapped to som standard ontologies).
For both steps, the generation of a semantic index requires more than just compilation of the retrieved data. Although the index might contain unstructured web-data including ontologies of well defined semantics, the main purpose of the index is to provide fast access to the information being represented in it. To generate the answer for a query, the search engine simply does not have enough time for performing
logical inferences to deduce knowledge (a.k.a. answers) online. Of course, this (logical inference) has to be deployed beforehand (i.e. offline), just in a similar way as the computation of today's
pageRank.
So, what is the use of machine processible semantics in a search engine's index data structure? The following possibilities can be considered (
the list is open for additional suggestions...):
- to add new cross-references between single index entries (associations),
- to find similarities between index entries ( = web data) w.r.t. their content, and
- to discover dependencies between single index entries to enable
- better visualization of the retrieved domain of information, and also
- efficient navigation to better fulfill the users information needs.
- of course also to disambiguate and to cluster web-data for better precision and recall (this is already done with current IR techniques).
To compile a semantic index, also the crawling process has to be considered. While the primary goal of a web crawler is to gather as much web-data as possible as fast as possible (and of course to maintain its level of consistency), a
'semantic' web crawler besides unstructured web-data also has to look for semantic data, as e.g., RDF and OWL files, and also for possible connections between unstructured web-data and semantic data. For crawling RDF or OWL, a traditional crawler has to be modified. While the traditional crawler just analyzes the HTML data for link tags, RDF and OWL don't contain link tags but they often include several namespaces that determine new input for the crawler. Besides mere data gathering, the crawler should also preprocess data for being included within the index. This task often is implemented as a separate step (and denoted as 'information retrieval'). But, it influences the crawlers direction and crawling strategy and thus, also has to be considered here.
Web crawlers often are implemented in a distributed way to increase their efficiency while working in parallel. New URLs found in the web pages being crawled can be arranged according to the location of their domain (
geographically). In this way, an instance of the distributed crawler receives only new URLs to be crawled that are located in the same (or a nearby) domain. The same argument holds for the resources that are to be crawled by semantic web crawlers. But, for semantic crawlers, also the (
semantic) domain of the crawled data might be of importance, e.g., an instance of the distributed crawler might be responsible for crawling a specific domain (=topic) or only domains that are (semantically) closely related to the domain of interest.
For the semantic search engine the compilation of an index from the web pages being delivered by the crawler differs from the compilation process of the traditional search engine. Let us first recall the
traditional index compilation process (for text related data, i.e. this does not hold for multimedia data such as images or video clips):
- resource normalization, i.e. all resources that contain explicit textual content have to be transformed into text files
- word stemming, i.e. transform all terms of a retrieved and normalized web-document to their word stems
- stop word removal, i.e. cut out all terms that are not well suited for identifying the processed text file (i.e. that are not suitable as descriptors). Often only nouns are taken as descriptors (this can partly be achieved by applying pos-stemmers (=part-of-speech stemmers).
- black list processing, i.e. terms that for some reason do not qualify as descriptors are cut out.
This process results in a list of descriptors that describe the web-document being processed. For each descriptor a weight according to its descriptive value for the text file has to be calculated (e.g., by
term frequency - inverse document frequency (tf-idf) or other weigth function). The table resulting from combining the weighted descriptors with their underlying web-documents constitutes the
index. By
inverting this index a descriptor delivers all related web-documents in combination with their pre-calculated weight function (that determines how well a given descriptor is suited to describe the content of the according web-document). To increase precision and recall, the general relevance of the web-documents can be computed beforehand (i.e. nothing else but the
Google PageRank).
For a 'semantic index', metadata (such as, e.g., ontologies) have to be taken into account and be combined with the traditional index...
...to be continued