 This morning, we were invited to a talk given by Thilo Götz from IBM about UIMA (Unstructured Information Management Framework), IBM's Framework for the Management of unstructured information that happened to take place at the department of computer linguistics.
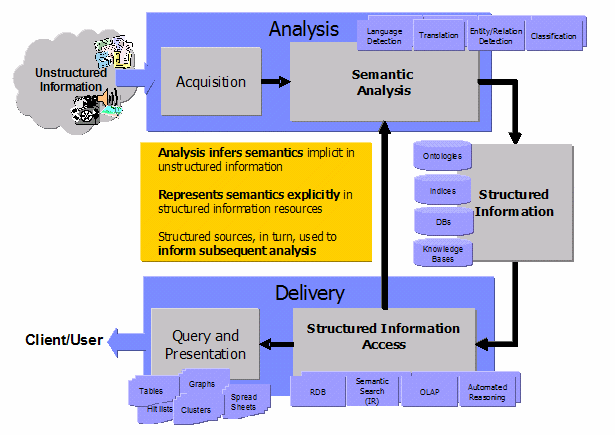
This morning, we were invited to a talk given by Thilo Götz from IBM about UIMA (Unstructured Information Management Framework), IBM's Framework for the Management of unstructured information that happened to take place at the department of computer linguistics.UIMA represents (1) an architecture and (2) a software framework for the analysis of ustructured data (just for the record: structured data refers to data that has been formally structured, a.g. data within a relational database, while unstructured data e.g., refers to text in natural language, speech, images, or video data). The purpose of UIMA is to provide a modular framework that enables easy integration and reuse of data analysis modules. In general, the UIMA framework distinguishes three steps in data analysis:
(1) reading data from distinguished sources
(2) (multiple) data analysis
(3) presentation of data/results to the 'consumer'
Also it enables remote processing (and thus simple parallelization of analysis tasks). Unfortunately, at least up to now, there is no GRID support for large scale parallel execution.
Also, simple applications of UIMA, e.g. in semantic search were presented (although their approach to semantic search means: do information retrieval on unstructured data and fit the resulting data into the index of the 'semantic search engine'...)
Nevertheless, we will take a closer look at UIMA. We are planning to map the workflow of our automated semantic annotation process (see [1]) into the UIMA architecture and I will tell you about our experiences made....
UIMA is available as a free SDK, and the core Java framework is also available as open source.
References:
[1] H. Sack, J. Waitelonis: Automated Annotations of Synchronized Multimedia Presentations, in Proceedings of Mastering the Gap : From Information Extraction to Semantic Representation (MTG06 / ESWC2006), Budva, Montenegro, June 12, 2006.