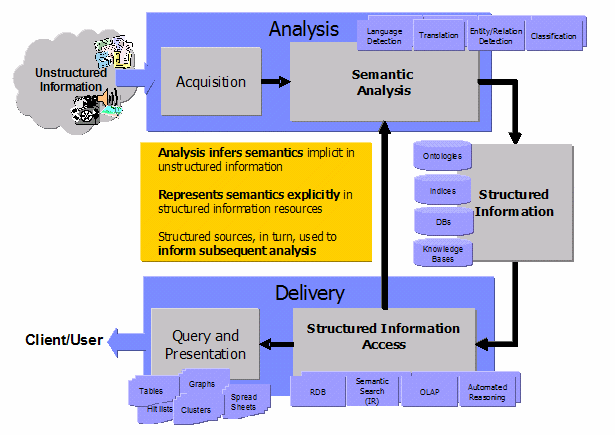
As mentioned in a
previous article, I decided also to write about (i.e. to review) the books I'm currently reading. I realized that my ability to express myself in English if it comes to the authoring of non scientific content is rather limited. Also I was thinking about whether it makes sense to write (in English) about books (written in German)...esp. if I want to address a German speaking audience (at least concerning the non-scientific content of this blog). Alas, the new beta-blogger allows the use of tags and thus, it will be possible to categorize articles (and to distinguish between content written in English or German). To make it short: from now on, book reviews for books of non-scientific content that are written in German will also be written in German. Everything else (including book reviews of books that I have read in English) will be written in English.
To all those who are also interested in those book reviews, you might consider to use
babelfish for translation (although I have no idea about the result:)...
Als ich vor wenigen Wochen die
ISWC besuchte, hatte ich mich ja bereits darüber beklagt, dass meine derzeitige Lektüre für das Handgepäck schlicht und einfach zu 'schwer' sei. Folglich stand ich vor dem Problem, was ich während der jeweils über 9 Stunden dauernden Flüge lesen sollte (natürlich habe ich währendessen auch geschlafen...so gut es eben ging...). Normalerweise lese ich nicht gerne mehrere Bücher parallel, und da ich es vermeiden wollte, nach meiner Reise mit zwei angefangenen Büchern dazustehen, entschied ich mich für Kurzgeschichten bzw. Erzählungen. Im Bücherschrank stand schon seit längerer Zeit ein kleines Bändchen mit
Erzählungen
von
Thomas Mann, für das zu lesen ich bis dato noch nicht die Muse aufbringen konnte. Da es (zumindest gewichtstechnisch) den Anforderungen an meine Reiselektüre entsprach, durchlebte ich also während des Fluges die Welt von 'Tonio Kröger', schmeckte den Fluch des 'Wälsungenblutes' und machte mich als Hunden gegenüber völlig indifferenten Zeitgenossen mit den Abgründen der Beziehungen zwischen 'Herr und Hund' vertraut....
Also gut, vielleicht sollte ich damit beginnen zu erwähnen, dass ich im Deutschunterricht niemals mit den Werken von Thomas Mann als Lektüre Bekanntschaft schließen musste. Viele meiner Bekannter stöhnen bereits laut auf, sobald nur der Name 'Thomas Mann' fällt...sicherlich, da sich unliebsame, bereits verdrängte Erinnerungen an die Untiefen der im Schulunterricht bis zum Erbrechen interpretierten und analysierten Soap-Opera '
Buddenbrooks
' ihren Weg zurück an die Oberfläche bahnten. Aber nicht bei mir. Die Buddenbrooks hatte ich das erste mal im 'zarten Alter' von knapp 30 Jahren vor mir. Ich dachte, "das reicht erst mal für die Weihnachtswoche", nur zog mich dieses Monstrum von einer Familiensaga derart in seinen Bann, dass ich es nach zweieinhalb Tagen (leise seufzend, da es 'schon' zu Ende war) wieder zurück ins Regal stellte. Allerdings kam neulich auf der Frankfurter Buchmesse während eines gemeinsamen Mitttagessens die Rede auf die wohl "am meisten überschätzten" deutschen Autoren. Nachdem ich meiner Nachbarin gegenüber mein Unverständnis ihrer Einschätzung, dass
Fontane dabei ganz oben auf ihrer Liste stehe, zum Ausdruck brachte, fiel mir daraufhin der '
Der Zauberberg
' und insbesondere der '
Doktor Faustus
' ein. Ohne mich jetzt hier zu vertiefen sei mir kurz der Hinweis gestattet "Thomas Mann hätte sich in meinem Gedächtnis sicherlich einen besseren Ruf behalten, hätte er zumindest auf das Schreiben des Letzteren der beiden genannten Romane verzichtet...".
Tonio Kröger
bietet dabei alle Höhen und Tiefen der Mann'schen Erzähltradition in kondensierter Form. Die relativ kurze Erzählung beginnt mit der Geschichte der Kindheit und des Heranwachsens Tonio Krögers in allerbesster kurzweiliger 'Buddenbrooks-Manier' und ergießt sich in der zweiten Hälfte in einer Introspektive (-> siehe Zauberberg) Tonios in seiner Rolle als Künstler (im Zwiegespräch und in Briefen an seine Künstlerfreundin Lisaweta). Im letzten Drittel unternimmt unser Held eine Reise zurück an die Stätten seiner Kindheit und beginnt zu begreifen, dass er als Künstler sehr wohl Teil der von ihm verächtlich abgelehnten 'Gesellschaft' ist und dass Gefühle einen Künstler nicht in seiner Arbeit hemmen, sondern gar bestimmen....(-> Wandlung siehe Doktor Faustus).
Fazit: Ein Kurztripp durch Thomas Manns Mikrokosmos, sehr zu empfehlen für alle, die in seine Welt mal 'kurz hineinschmecken' wollen, ohne das Wagniss eingehen zu müssen, sich einem der vorgenannten 'Monstren' zu stellen :)
Das
Wälsungenblut
ist da schon etwas anders gestrickt - auch wenn die eindrucksvoll plastische Schilderung dieser etwas kurios dekadenten Bankiersfamilie Aarenhold stellenweise an die
Addams-Family erinnert.... Thomas Mann karikiert dabei den schwülstige Pathos der Opern-Atmosphäre
Richard Wagners - hier ganz speziell die der
Walküre. Geschildert wird die inzestiöse Liebe des Wälsungen-Geschwisterpaares Siegmund und Sieglinde, wobei es Mann gelingt, eine durch Liebe zum Detail perfekte Inszenierung abzuliefern, die vom Kunstgenuss des Opernzitats mit Kognak-Kirsche bis hin zum Liebesreigen auf dem Bärenfell (-> siehe Wagners Walküre) reicht.
Fazit: ein kurzweiliges Stück skuriler Prosa, in dem sich Thomas Mann als Meister der pointierten Schilderung und 'Anti-Wagnerianer' erweist...